BedrockにPowerPointファイルの中身の日本語部分を校正してもらう
背景
出来上がったお客様向けの提案書(.pptx形式のPowerPointファイル)を、仕上げとして体裁レビューを依頼するとします。これはあくまで最後に「体裁」を整えるという意味で、見栄えや統一感、日本語文章の校正、表のズレなど非常に多義に渡ります。
例えば以下は体裁レビューの一例です。
P2:目次の4.プロジェクト管理のページがズレてます
P15:6行目「(Linux only) 」→()全角にと、Linuxonlyでは無いでしょうか?
P17:初期費用の合計だけ太文字になっています
P17:月額費用表の合計が無いのですがあった方がいいかと思います
P20:9行目「(含みます)」→()全角に
P23:見出しの「2−2」→2−3
問題は人が目視でやっているため、レビュー者の主観やレビュー者によって指摘点がまちまちだということ、もちろん人的コストも掛かっています。
目的・やりたいこと
そこで、この体裁レビューをBedrockにやらせるAIレビューを挟むのはどうかと考えました。もちろん最初のうちはLLMやプロンプトの未熟さで人による体裁レビューほどの正確・柔軟な指摘は難しいかもしれませんが、最初は併用⇨徐々に改善を重ねて人に置き換わることができればと思っています。
生成AIレビューの問題点
ファイルを噛ませるくらいであれば、巷の無料生成AIサイトに投げてレビューして貰えばいいのでは?ということで幾つか試しましたが、次の問題点が浮かび上がりました。
- ファイル投稿に対応していないものが多い(Perplexity、Geminiなど)
- Bedrockはファイルに対応しているが、pptx拡張子には対応していない
チャットのプレイグラウンド
Chat with your document

- ChatGPTなどはpptxファイルに対応しているが、プロンプトが悪いのか、以下のような差し障りのない指摘しか返ってこないことが多い
全体的に文の流れやフォーマルなトーンは適切です。しかし、一部の表現がやや長く、文のリズムが崩れがちなので、もう少し簡潔にまとめると、さらに読みやすくなります。
提案書として、技術的な内容の正確性が重要ですが、ビジネスライクな敬語や表現を使用することで、より丁寧で洗練された印象を与えることができます。
- 短文の文章であれば、文章部分を直接貼り付けて生成AIに回答させることもできるが、提案書は50ページ(2MB)くらいあるのがザラ
- ファイルサイズに制限がある
- 無料版だと1日の試行回数に制限がある
- 何より無料でWebで公開されている生成AIサイトに機密ファイルを投げることがなんとなくセキュリティ的に不安
- Slack内で気軽にファイルを貼り付けたい
そこで、SlackからAWS(Lambda⇨Bedrock)と連携して、レビュー結果をSlackに表示させるというアプリを作ることにしました!
対象となる技術
条件(導入にあたっての前提事項)
- LLMモデルには当初現時点で文系思考日本語最強LLMと言われる「Claude 3 Opus」を使おうと思いましたが、比較してみた結果、最新の高性能「Claude 3.5 Sonnet」を採用することにしました。この辺りはもっといいモデルが出たら随時置き換えていこうと思います。
- Lambdaに付与したBedrock_S3.roleには、次のロールをアタッチ
参考URL
- Claude3を使ってパワポ資料を読み込む処理をLambda関数上で実行してみた | DevelopersIO
- Anthropic Claude メッセージ API - Amazon Bedrock
- Bedrock+サーバレスでSlackボットを作成してみた
- Slack Events APIの再送仕様と回避方法まとめ(Serverless on AWS) | DevelopersIO
注意事項
- コードに関しては絶対にこれが正しいという保証はありません。余分な処理やモジュールも含まれてしまっていると思います。あくまで参考程度に留め、自分でカスタマイズして使ってください。
- 今回はSlackアプリ部分にBoltやLazyリスナーという仕組みを使用しています。Slackアプリに特化した部分となるため、本格的に説明すると本質からズレるため、詳細は上記リンク先を参考にしてください。
概要図

作業の流れ
事前作業
1.機密情報を含まない架空の提案書を用意
2.以下の内容の3つのファイルを作成
requirements.txt
Dockerfile
FROM public.ecr.aws/lambda/python:3.12
# コンテナの作業ディレクトリを設定
WORKDIR /var/task
RUN echo sslverify=false >> /etc/yum.conf
# libreoffice に必要なパッケージをインストール
RUN dnf -y install tar gzip zlib freetype-devel make bison libxslt wget\
gcc ghostscript lcms2-devel libffi-devel libjpeg-devel libtiff-devel \
libwebp-devel openjpeg2-devel tcl-devel tk-devel xorg-x11-server-Xvfb \
zlib-devel java ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts \
&& dnf clean all
# libreoffice をインストール
RUN wget https://download.documentfoundation.org/libreoffice/stable/24.2.5/rpm/x86_64/LibreOffice_24.2.5_Linux_x8
6-64_rpm.tar.gz --no-check-certificate && \
tar -xvzf LibreOffice_24.2.5_Linux_x86-64_rpm.tar.gz && \
cd LibreOffice_24.2.5.2_Linux_x86-64_rpm/RPMS && rpm -iUvh *.rpm && \
rm *.rpm && cd ../
RUN dnf -y install cairo
# pdf2img に必要なパッケージをインストール
RUN dnf -y install poppler-utils python3 python-pip
# 必要なPythonパッケージをインストール
COPY ./requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org
# 必要なファイルをコンテナにコピー
COPY ./app.py ${LAMBDA_TASK_ROOT}
ENV HOME=/tmp
ENV SLACK_BOT_TOKEN="xoxb-****"
ENV SLACK_SIGNING_SECRET="bc****"
# ハンドラー情報
CMD ["app.handler"]Dockerfileのポイント
- libreofficeをパッケージインストール
libreofficeをyumなどで入れると古いバージョンで入ってしまい、最新のpython-pptx 1.0.2に対応できないため、LibreOffice 24.2.5のRPMパッケージをダウンロードしてきて入れる必要がありました。 - FROM public.ecr.aws/lambda/python:3.12
LibreOffice 24.2.5を入れるためにDockerのOSをAmazon Linux 2023にする必要があるため、それに対応したpython 3.12をここで指定しています。
▼app.py
import json
import boto3
import re
import os
import requests
from pptx import Presentation
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from io import BytesIO
from slack_bolt import App,Ack
from slack_bolt.adapter.aws_lambda import SlackRequestHandler
# 環境変数推奨(トークン直書きは非推奨)
SLACK_BOT_TOKEN = os.environ.get("SLACK_BOT_TOKEN")
SLACK_SIGNING_SECRET = os.environ.get("SLACK_SIGNING_SECRET")
# Slack APIクライアントを初期化
client = WebClient(token=SLACK_BOT_TOKEN)
# Boltアプリケーションを初期化
app = App(
token=SLACK_BOT_TOKEN,
signing_secret=SLACK_SIGNING_SECRET,
process_before_response=True
)
# Bedrock呼び出し
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-west-2")
def just_ack(ack):
ack()
def handle_mention(event, context):
# JSON文字列をPythonの辞書に変換する
channel = event.get("channel")
type = event.get("type")
# スレッドのタイムスタンプを取得
thread_ts = event.get("thread_ts")
# thread_ts が None の場合、元のメッセージのタイムスタンプを使用
if thread_ts is None:
thread_ts = event.get("ts")
# スレッドメッセージを取得
response = client.conversations_replies(channel=channel, ts=thread_ts)
message = response['messages'][0]
if "files" in message:
for file in message["files"]:
# ファイルのタイプを確認# 添付ファイルがpptxファイルの場合
if file["filetype"] == "pptx":
file_url = file["url_private_download"]
# ファイルをダウンロード
response2 = requests.get(file_url, headers={"Authorization": f"Bearer {client.token}"})
# レスポンスのステータスコードをチェック
if response2.status_code == 200:
# ファイルコンテンツを取得
file_content = response2.content
pptx_file = file_content
slides_text = extract_text_from_pptx(pptx_file)
corrected_text = process_slides(slides_text)
# Slackのチャンネルに投稿
client.chat_postMessage(
channel=channel,
thread_ts=thread_ts,
text=f"校正結果:\n{corrected_text}"
)
return {"statusCode": 200}
# pptxファイルからテキストを抽出する関数
def extract_text_from_pptx(pptx_content):
prs = Presentation(BytesIO(pptx_content))
slides_text = []
for i, slide in enumerate(prs.slides, 0):
slide_text = f"スライド{i}:\n"
for shape in slide.shapes:
if hasattr(shape, 'text'):
slide_text += shape.text + '\n'
if shape.has_table:
for cell in shape.table.iter_cells():
for text in cell.text.splitlines():
slide_text += text + '\n'
slides_text.append(slide_text)
return slides_text
# スライドを処理する関数
def process_slides(slides_text, batch_size=5):
results = []
for i in range(0, len(slides_text), batch_size):
batch = slides_text[i:i+batch_size]
batch_text = "\n\n".join(batch)
result = bedrock_check(batch_text)
# 不要な回答を除去
filtered_result = filter_unnecessary_responses(result)
if filtered_result.strip(): # 空の結果を除外
results.append(filtered_result)
time.sleep(1) # APIリクエストの間隔を空ける
return "\n\n".join(results)
# Bedrockで校正させる関数
def bedrock_check(text):
prompt = f"""あなたは日本語の校正と文書フォーマットの専門家です。
以下の指示に従って、パワーポイントファイル内のテキスト部分を抽出したテキストファイルの内容を徹底的にチェックしてください:
1. 内容チェック:
- 公開すべきでない情報や、社内限りの情報が含まれていないか
- お客様に対して失礼または不適切な表現
- 業界用語や専門用語の適切な使用
2. 文法チェック:
- 敬語(尊敬語、謙譲語、丁寧語)の適切な使用
- 誤字脱字(スペルミスや漢字の間違いがないか、句読点の使用が適切か)
- 文法的な誤り
3. スタイルチェック:
- 一貫性のある文体
- 簡潔で明瞭な表現
- 自然な日本語表現になっているか
- 用語の使用が文書全体で統一されているか
4. フォーマットチェック:
- フォントの一貫性(種類、サイズ)
- 太字、斜体、下線の適切な使用
- 文字間隔、行間の統一性
- 箇条書きや番号付きリストの一貫性
5. お客様に対する配慮:
- 失礼または不適切な表現がないか
- ビジネス文書として適切な丁寧さが保たれているか
6. テーブルチェック
- 表内に数値があった場合、その数値の合計などが合っているか
- 誤字脱字がないか
各スライドを順番にチェックし、指摘事項がある場合のみ以下の形式で報告してください。
スライド番号:
- [カテゴリ] 具体的な問題点と修正案
チェック対象のテキスト:
{text}
"""
content_prompt = {
"type": "text",
"text": prompt,
}
content = [content_prompt]
messages = [
{"role": "user", "content": content},
]
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 8192,
"temperature": 0,
"messages": messages,
}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId="anthropic.claude-3-opus-20240229-v1:0",
# modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
corrected_text = response_body['content'][0]['text']
return corrected_text
# 不要な指摘を排除する関数
def filter_unnecessary_responses(text):
# スライド番号ごとに分割
slides = re.split(r'(スライド\d+:)', text)
filtered_slides = []
for i in range(1, len(slides), 2):
slide_header = slides[i]
slide_content = slides[i+1] if i+1 < len(slides) else ""
# "指摘事項はありません" や "特に問題ない" などの不要な回答を含まないスライドのみを保持
if not re.search(r'指摘事項(は|が)ありません|特に問題(は|が)ない|該当なし|指摘事項なし', slide_content, re.IGNORECASE):
filtered_slides.append(slide_header + slide_content)
return "\n".join(filtered_slides)
# Lazy listeners
app.event("app_mention")(ack=just_ack, lazy=[handle_mention])
# Lambda用ハンドラー
def handler(event, context):
header = event.get('headers', {})
# ヘッダーにx-slack-retry-numが入っていたらリトライなので終了にする
if "x-slack-retry-num" in header:
return 200
else:
slack_handler = SlackRequestHandler(app=app)
return slack_handler.handle(event, context)app.pyのポイント
- Boltアプリケーション
Boltとは、リスナー関数などを使って様々なイベントに応答するインタラクティブなSlackアプリを開発するフレームワークです。JavaScript(Node.js)、Python、Javaに対応しており、今回Bolt for PythonでLazy Listenersという機能を使う目的のため、入れました。
Bolt 入門ガイド | Bolt for Pythonより、以下を行うことで実装できます。
pip install slack_bolt
import os
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
app = App(token=os.environ.get("SLACK_BOT_TOKEN"))
- Slackからファイルをダウンロード
file_url = file["url_private_download"]
# ファイルをダウンロード
response2 = requests.get(file_url, headers={"Authorization": f"Bearer {client.token}"})
【Python】SlackbotでSlackからファイルをダウンロードする - みやびのどっとぴーわい を参考に、まずfile["url_private_download"]でファイルのURLを取ってきます。次に、そのURLを指定して実際のファイルをダウンロードします。その際にAPIトークンの指定が必要になります。headers={"Authorization": f"Bearer {client.token}"}
- python-pptxライブラリ
python-pptxとは、プレゼンテーション形式ファイル(.pptx)を作成できるpythonライブラリです。今回pptxファイルを読み込んでテキストを抽出するため導入しました。
Pythonでパワポ資料(スライド)作成を自動化しよう! - AI Academy Mediaより、以下を行うことで実装できます。
pip install python-pptx
from pptx import Presentation
prs = Presentation() # Presentationクラスをインスタンス化
- Bedrockのプロンプト
prompt = f"""あなたは日本語の校正と文書フォーマットの専門家です。
以下の指示に従って、パワーポイントファイル内のテキスト部分を抽出したテキストファイルの内容を徹底的にチェックしてください:
1. 内容チェック:
〜〜
2. 文法チェック:
〜〜
ここはかなり苦労しましたし、今回の「日本語校正」というテーマでは最も肝になる部分です。箇条書きが長すぎると、
- 内容チェック:問題ありません
- 文法チェック:問題ありません
というように全部「問題ありません」で終わってしまいます。ですのでチェックポイントの羅列は長すぎず短すぎずの程よいバランスを見つけることが大事です。
-
回答のランダム性を極力減らすため、Bedrockのtemperature(温度)は0に設定
温度:ランダム性の度合いを調整するために使用される数値(デフォルト0.9、0〜5)
生成モデルからのサンプリングにはランダム性が組み込まれているため、同じプロンプトでも世代ごとに異なる出力が生成される場合があります。応答のランダム性を減らすには、より低い値を使用します。 -
Lazy listeners
Lazy(怠慢な)リスナーとは、非同期処理を別のLambda関数へ割り当てる機能です。
Lazy リスナー(FaaS) | Bolt for Pythonに記載されているように、「lazy=」で非同期処理関数を呼び出しています。
app.event("app_mention")(ack=just_ack, lazy=[handle_mention])
- X-Slack-Retry-Num
X-Slack-Retry-NumというHTTPヘッダーに「X-Slack-Retry-Num:1」のようにリトライの回数の情報が含まれているので、このヘッダーが含まれているときは200を返して終わらせています。
header = event.get('headers', {})
if "x-slack-retry-num" in header:
return 200
Slackアプリの登録
slack apiにてアプリを登録します。
1.Create an appで「From scratch」を選びます。
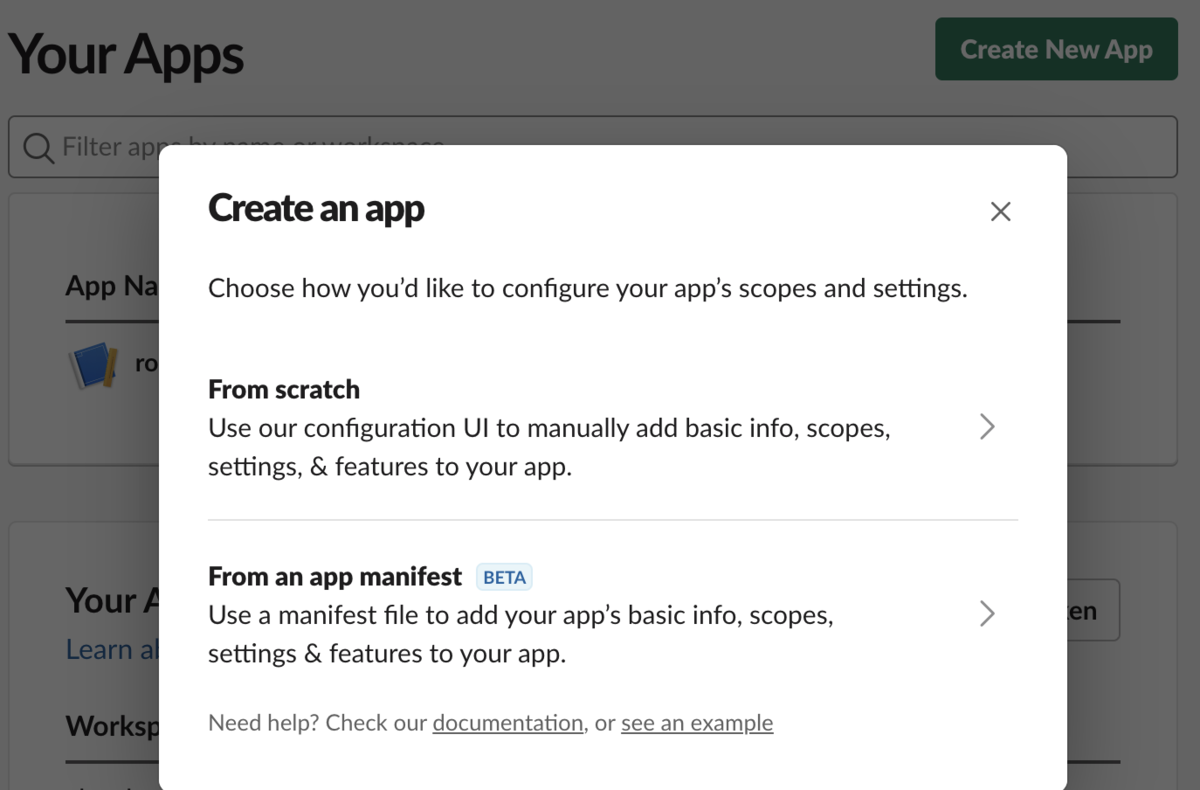
2.アプリ名と導入するワークスペースを選んで[Create App]

3.Slackから呼び出すURLを決める
アプリは、選択したURLでSlackのイベント(ユーザーがリアクションを追加したり、ファイルを作成したときなど)の通知を受け取るようにサブスクライブできます。この際に用いるリクエストURLを決めるため、ここは一旦保留して、後のLambdaが準備できた後にまた戻ってくることにします。
手順
コードをECRリポジトリにPUSH
手元のMacかCloud 9どちらでもいいので、用意した3つのファイルを次のように配置し、ビルドからPUSHまでdockerコマンドが使えるdocker環境で下記作業を行います。
pptxディレクトリ
├Dockerfileファイル
├requirements.txtファイル
└app.pyファイル
1.ビルド
% docker build -t nozaki-rep .
[+] Building 26.6s (16/16) FINISHED docker:desktop-linux
=> [internal] load build definition from Dockerfile 0.0s
〜〜〜
=> => naming to docker.io/library/nozaki-rep 0.0s
What's next:
View a summary of image vulnerabilities and recommendations → docker scout quickview
2.タグ付け
% docker tag nozaki-rep:latest 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/nozaki-rep
3.ECRログイン
% aws ecr get-login-password --region ap-northeast-1 --no-verify | docker login --username AWS --password-stdin 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com
urllib3/connectionpool.py:1063: InsecureRequestWarning: Unverified HTTPS request is being made to host 'api.ecr.ap-northeast-1.amazonaws.com'.
Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
Login Succeeded
4.PUSH
% docker push 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/nozaki-rep
Using default tag: latest
The push refers to repository [123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/nozaki-rep]
cf7c7eefe9c2: Pushed
456541b5bfba: Pushed
c8d68278ba1b: Pushed
5ac14a4ce153: Pushed
efc06e5766e7: Pushed
93d6f734e916: Pushed
58c3eb3010cf: Pushed
5f142f1e76fb: Pushed
32d6a65b3647: Pushed
5f70bf18a086: Pushed
0274404cdadc: Layer already exists
3afe23385c51: Layer already exists
c88f3983c839: Layer already exists
f5e83de1dfd4: Layer already exists
0d39f7236e4f: Pushed
0044b36762be: Layer already exists
latest: digest: sha256:d*******Lambda環境の作成
1.Lambda > 関数 > [関数の作成]
2.関数の作成
コンテナイメージからデプロイするため、[コンテナイメージ]を選択し、以下のように入力

3.実行ロール
条件で用意していたBedrock_S3.roleを選択

最後に[関数の作成]
4.[イメージ]タブ > [新しいイメージをデプロイ]

5.イメージを参照
ECRイメージリポジトリで先ほど作成した「nozaki-rep」を選択
イメージタグが「latest」になっている[イメージを選択]して[保存]

「更新中です」と表示され、1分くらいかかるので待つ
6.Lambda関数名など側を作成したら、設定⇨関数URLで「関数URLを作成」してLambda関数のURLを生成します。

7.認証はNone(なし)で大丈夫です。
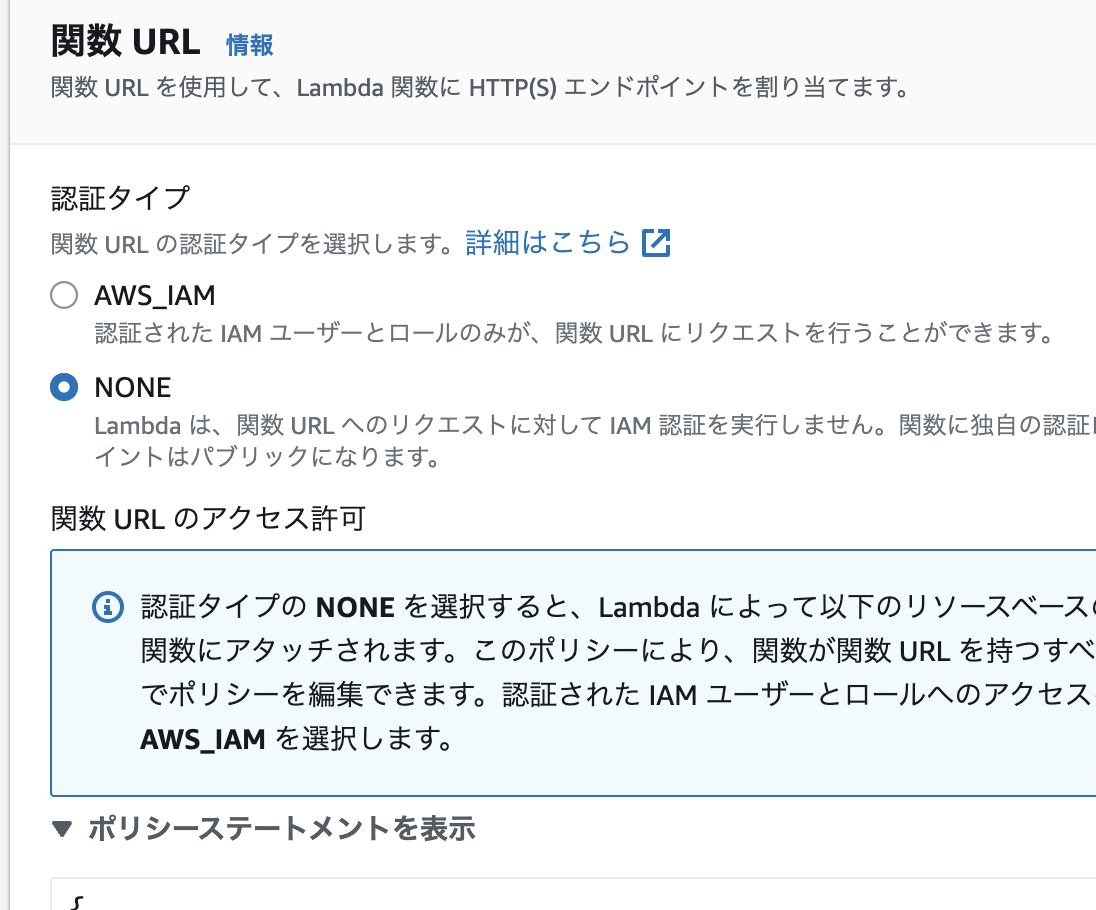
8.[保存]すると、以下のような関数URLが生成

その他Lambdaの設定値調整
タイムアウトと再試行数を設定して、Lambda関数が複数回実行される不具合を修正してみた | DevelopersIO を読むと、タイムアウトが短く再試行回数があるとLambdaが何度も実行されてしまうようなので、パラメータを調整します。
-
タイムアウト
デフォルトの3秒では短すぎるので、10分と十分長くしておきました。実際6分くらいかかるので
-
非同期呼び出し再試行数
2回になっていたので0に。また最大有効期間も60時間じゃ長すぎるので10分にしました。
再びslack apiに
1.アプリのFeatures⇨Event Subscriptions⇨Enable EventsをOnにします。

2.Request URLに前手順3.で生成した関数URLを入れるのですが、その前に少しコードをいじります。
イベントが発生すると、HTTP POSTリクエストがこのURLに送信されます。URLを入力するとすぐに、challengeパラメータを含むリクエストが送信されます。エンドポイントはこのchallenge値で応答する必要があるため、次のコードを追加します。
def lambda_handler(event, context):
data = json.loads(event["body"])
if "challenge" in data:
return {"statusCode": 200, "body": data["challenge"]}
これでVerifiedになりました。

一旦これが通りさえすれば、後から上記のコードを外しても構いません。
3.Subscribe to bot events
アプリは、ボット ユーザーがアクセスできるイベント(チャネル内の新しいメッセージなど)を受信するためにサブスクライブできます。つまり、どんな時にslack botを発動させるかをここで定義します。アプリをメンションした時だけ発動する「app_mention」を選択し、[Save Changes]

4.OAuth & Permissions
Lambdaのコード内で使うことになるBot User OAuth Token(xoxb〜で始まる)をメモしておきます。

次に、slack botに何をできるようにさせるかの権限を付与します。

ここでは以下を付与しました。
- app_mentions:read
アプリが参加している会話で、アプリについて直接言及しているメッセージを表示する - calls:read
進行中および過去の通話に関する情報を表示 - calls:write
ワークスペースで通話を開始および管理 - channels:history
アプリが追加されたパブリックチャネルのメッセージやその他のコンテンツを表示 - channels:join
ワークスペースのパブリックチャンネルに参加 - channels:read
ワークスペース内のパブリック・チャンネルの基本情報を表示 - chat:write
メッセージをアプリとして送信 - groups:history
アプリが追加されたプライベートチャネルのメッセージやその他のコンテンツを表示 - groups:read
アプリが追加されたプライベートチャンネルの基本情報を見る - im:history
アプリが追加されたダイレクト メッセージ内のメッセージやその他のコンテンツを表示 - im:read
アプリに追加されたダイレクトメッセージの基本情報を見る - incoming-webhook
Slackの特定のチャンネルにメッセージを投稿 - mpim:history
アプリが追加されたグループダイレクトメッセージのメッセージやその他のコンテンツを表示 - mpim:read
アプリが追加されたグループダイレクトメッセージの基本情報を見る - users:read
ワークスペース内のユーザーを表示 - users:write
アプリのプレゼンスを設定 - files:read
アプリが追加されているチャンネルや会話で共有されているファイルを表示
5.ワークスペースへのアプリのインストールが完了すると、OAuthトークンが自動的に生成されます。これらのトークンを使用してアプリを認証します。
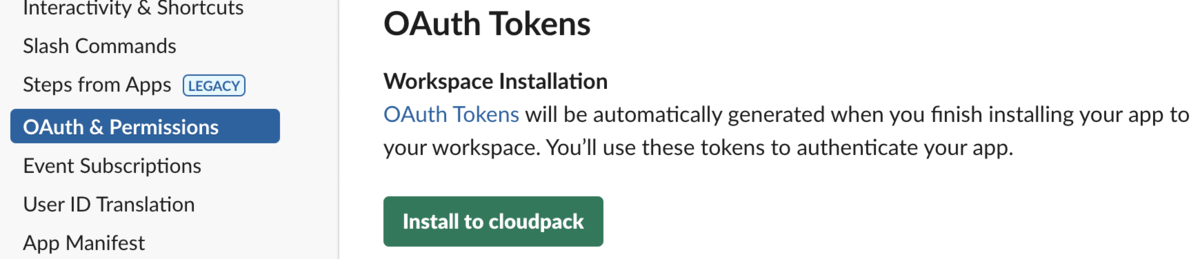

これでようやくBot User OAuth Tokenが生成されるため、メモしておきます。

6.アプリをチャンネルに参加

苦労ポイント:Slack特有の3秒ルール
ファイルが2MBあってPostされるまで時間かかるせいか、最初のSlack⇨Lambdaで何度もLambdaをInvocationしてるようで、同じレスが何度も入ってしまっていました。

この辺りの問題については、Slack Events APIの再送仕様と回避方法まとめ(Serverless on AWS) | DevelopersIO がよくまとまっています。
システム的にSQSを挟んでキューイングしたり、LambdaからLambdaをキックする方法もあるようですね。
他に対処的だけど、リトライ無視するようにしてます。
def ignore_retry_request(request, ack, next):
"""リトライを無視する関数"""
if "x-slack-retry-num" in request.headers:
return ack()
next()
app.use(ignore_retry_request)
こちらはif文を使ってヘッダーを見て回避しました。
モジュール側で実装されているLazy Listeners機能を使った小技は、Bolt for Python が FaaS での実行のために解決した課題 #AWS - Qiita が詳しかったです。
以上により、CloudWatchでもこのように2回の発動で済んでいます。



目的達成!
@PowerPoint Proofreadingをメンションしてpptxファイルを投稿します。

すると、5分経過後、そのスレッド内にリプライ(2回に分けてるので2件)して、日本語文章の校正をして指摘してくれるようになりました!

モデルは結局どれがいいの?
ここでClaude 3 opusとClaude 3.5 sonnetどちらのAnthropicモデルを採用すべきか、その指摘結果を比較して判断することにしました。50スライド全部比較すると大変なので、最初の10スライド分だけ見てみます。
| LLM | Claude 3 opus | Claude 3.5 sonnet |
|---|---|---|
| スライド1 | [文法チェック] 「弊社は、2003年に創業してから常に、一歩進んだソリューションを提供し続けるパートナーとして、大企業に引けを取らない高品質な開発を実現してまいりました。」の文が長く、読みにくいです。文を分割することをおすすめします。修正案:「弊社は、2003年の創業以来、常に一歩進んだソリューションを提供し続けるパートナーとして歩んでまいりました。大企業に引けを取らない高品質な開発を実現してきたことが弊社の強みです。」 | [文法チェック] "引けを取らない"は"引けを取らない"が正しい表記です。 [スタイルチェック] "パブリッククラウド(AWS, Azure, GCP)"の括弧内はカンマの後にスペースを入れるのが一般的です。修正案: "パブリッククラウド(AWS, Azure, GCP)" |
| スライド2 | [フォーマットチェック] 目次の各項目の字下げにばらつきがあります。インデントを統一することをおすすめします。 [フォーマットチェック] ページ番号の位置が統一されていません。ページ番号は右下に配置するのが一般的です。 |
[フォーマットチェック] 目次の番号付けが一貫していません。例えば、"4. プロジェクト管理"の後に"5. 監視・運用保守"がありますが、その間に番号のない項目があります。 [スタイルチェック] "Appendix"は日本語文書では"付録"とするのが一般的です。 |
| スライド4 | - [文法チェック・スタイルチェック] 「弊社対応方針」の箇条書きの文末が統一されていません。「〜致します」「〜しております」「〜致します」となっています。「〜いたします」で統一することをおすすめします。 [誤字脱字] 「下記2通り提示させていただきす」の「きす」は誤字です。「きます」が正しいです。 |
[文法チェック] "CLOUDからAWSへの移行"の"CLOUD"は小文字が適切です。 [スタイルチェック] "F社"という表記は、実際の社名を伏せているものと思われますが、文書全体で一貫して使用されているか確認が必要です。 [文法チェック] "提示させていただきす"は"提示させていただきます"の誤りです。 [フォーマットチェック] 箇条書きの形式が一貫していません。一部の項目にのみ丸点(・)が使用されています。 |
| スライド5 | [文法チェック] 「移行検討中の対象サーバは下記100台を想定しております。」の文末表現が不適切です。「想定しています。」や「想定しております。」に修正することをおすすめします。 [文法チェック] 表内の「Zabix監視サーバ」のスペルミスがあります。「Zabbix監視サーバ」が正しいスペルです。 [スタイルチェック] 表内の文章の末尾が「。」で統一されていません。文章の終わりには「。」をつけるように統一することをおすすめします。 |
[内容チェック] "Zabix監視サーバ"は"Zabbix監視サーバ"の誤りだと思われます。修正をお勧めします。 [フォーマットチェック] 表の列幅が不均一です。特に"備考"列が狭く、内容が読みにくくなっています。列幅を調整することをお勧めします。 |
| スライド6 | [文法チェック] 「本プロジェクトにおけるスケジュールは下記の通りを想定しておりす。」のスペルミスがあります。「想定しております。」が正しい表現です。 [フォーマットチェック] 表内のフォントサイズがばらばらで統一されていません。フォントサイズを統一することをおすすめします。 |
[文法チェック] "想定しておりす。"は"想定しております。"の誤りです。修正が必要です。 [フォーマットチェック] 表の列幅が不均一で、特に月の列が狭くなっています。調整をお勧めします。 [スタイルチェック] "9月"のみ全角数字になっています。他の月と統一して"9月"とすることをお勧めします。 |
| スライド8 | [文法チェック] 「移行進捗に必要なミーティングへの同席、情報整理・提供」が箇条書きになっていません。他の項目と同様に箇条書きにすることをおすすめします。 [フォーマットチェック] 想定参画メンバーの人数表記が数字のみになっています。「名」を追加して「100名」のように統一することをおすすめします。 |
[フォーマットチェック] "想定参画メンバー"の表で、人数が100名、101名となっていますが、これは誤りの可能性が高いです。実際の想定人数に修正することをお勧めします。 |
| スライド9 | [文法チェック] 「移行進捗に必要なミーティングへの同席、情報整理・提供」が箇条書きになっていません。他の項目と同様に箇条書きにすることをおすすめします。 | [フォーマットチェック] "想定参画メンバー"の表で、人数が100名、200名となっていますが、これも誤りの可能性が高いです。実際の想定人数に修正することをお勧めします。 表のフォーマットが一貫していない箇所があります。特に列幅や行高さの調整が必要な箇所があります。 数値の表記(特に人数)に不自然な点があります。実際の数値を確認し、修正することをお勧めします。 |
| スライド10 | [内容] "Zbix監視サーバ"は一般的な用語ではないため、"Zabbix監視サーバ"に修正することを提案します。 [内容] "New Relic"は製品名のため、"New Relic"とすべきです。 [スタイル] "致します"は少し硬い表現なので、"いたします"に変更することをおすすめします。 [フォーマット] 箇条書きの記号が"※"となっていますが、他のスライドでは"・"が使用されているため、統一することを推奨します。 |
[誤字] "Zbix" → "Zabbix" [文法] "検討致します。" → "検討いたします。"(謙譲語の使用) [一貫性] "構成案①" と "構成案②" の後に句点がないため、追加するか両方とも省略するか統一すべき |
どうでしょうか?お?と思う際立った指摘だけ太字にしてみたのですが、Claude 3.5 sonnetの方がその傾向が顕著だった気がします。
でもきっとお高いんでしょう?
試算してお見積もり出してみました。実質的な料金が発生しそうなのはLambdaとBedrockです。
- Lambda
体裁レビューが大体1日に1回、1ヶ月で20回=リクエスト数=20回/月
1リクエストにつき5分かかるため、5分=5分/秒×60秒/分×1,000ミリ秒/秒 =300,000ミリ秒
20リクエスト/月×300,000ms/リクエスト×0.001s/ms=6,000(秒/月)
割り当てたメモリ: 256MB×1/1024 (GB/MB)=0.25GB
0.25GB×6,000秒=1,500コンピューティング(GBs/月)
Lambdaの無料利用枠には、毎月1,000,000件の無料リクエスト、毎月400,000GB秒のコンピューティング時間が含まれているため、無料利用枠に軽々と収まってしまう。 - Bedrock
On-Demandのテキスト⽣成モデルでは、処理された⼊⼒トークンと⽣成された出⼒トークンごとに課⾦されます。
基盤モデルを使用した生成 AI アプリケーションの構築 – Amazon Bedrock の料金表 – AWS のAnthropicのオンデマンド料金のClaude 3.5 Sonnetの行を見ると、
入力トークン1,000個あたりの価格:0.003 USD
1,000出力トークンあたりの料金:0.015 USD
生成AIに聞いたところ、架空の提案書は約10,000トークン、Slackへのリプライ文章は約5,000トークンとなったことから、
入力トークン料金=0.003(USD/1000トークン)×10,000トークン/1,000トークン×140(円/USD)=4.2円/リクエスト
出力トークン料金=0.015(USD/1000トークン)×5,000トークン/1,000トークン×140(円/USD)=10.5円/リクエスト
つまり、1リクエストにつき合計14.7円かかっている。これに20リクエスト/月を乗じると、294円/月
ということで、合計月額 300円 も行ってない計算になりました。
安全性(セキュリティ)
このアプリで唯一懸念することがあるとすれば、提案書の中身の漏洩です。実際にお客様に送信する予定の社外秘情報の提案書を生成AIに掛けるわけですから、情報漏洩などがあったら大変です。
- Slack
何か脆弱性があったりしない限りはSlackアプリに問題が生じることはないと思っています。 - AWS
Amazon Inspectorを有効にし、実行中のLambda関数とECRリポジトリにスキャンを行い、ソフトウェアの脆弱性と意図しないネットワークのエクスポージャーを検出するようにします。 - Bedrock
AWSはBedrockがインプットした情報を漏洩させることがないことを前から謳っているので、セキュリティ攻撃に備えておけばいいかと思います。この辺りは別の機会で別途Bedrock活用安全セキュリティガイドラインみたいなものを作成し、上司を安心させたいです。
あとは個人情報を一切出さないようガードレールを設定し、提案書に野崎の個人情報をあえて含ませてみたところ、以下のレスポンスが返ってきたので、誤って個人情報を回答してしまわないことも確認できました。
- [内容チェック] 個人情報(メールアドレス、電話番号、住所)が含まれています。公開すべきでない情報のため、削除または匿名化が必要です。
改善点
- 全てを鵜呑みにしてはいけない
例えば「「致します」は「いたします」と表記するのが一般的です。」などは特に従わなくてもよいどっちでもいい指摘だったりします。この辺りはプロンプトの工夫次第で改善の余地がまだまだありそうです。 - ファインチューニング
日本語の校正をするだけなのでこの辺りのトレーニングは特に不要そうな気はしますが、活用していくうちにこういった指摘をするようにしてほしいとか、この程度の知識は持っていてほしいなどAIに対する要望が出てくるかもしれません。
ユースケース・活用例
- 提案書のレベルアップ
今回はあくまでお客様へ提出する上で恥ずかしくない日本語を整えるという観点で体裁レビューだけを行いましたが、提案書の内容をもっとレベルアップさせることにも活用できると思います。例えば、本提案書でもっとアピールした方がいい部分、追加した方がいい部分、逆に削った方がいい不要な部分を指摘してもらうというような使い方です。
- 他のフォーマット形式のファイルへ応用
今回はpptxファイルに特化してその変換関数まで用意しましたが、本アプリを基にして活用すれば、色々なフォーマット形式のファイルをBedrockに食わせてその中の日本語文章部分の校正などを行わせることができるようになると思います。
まとめ
- PythonでPowerPointを操作するには、python-pptxという外部ライブラリが必要
- プロンプトで文章校正を促すには、チェックポイントを箇条書きで羅列すると良い
- Slackの3秒ルールに注意。LazyリスナーとX-Slack-Retry-Numヘッダーで対策
- 現時点で日本語文章に強そうなLLMはClaude 3.5 sonnetと推測
- Bedrockへの入力・Bedrockからの出力は、どのモデルプロバイダーとも共有されず、Titanまたはサードパーティのモデルをトレーニングすることはない
- ガードレールを使って機密コンテンツの出力を防ぐ
- 生成AIの指摘は参考程度にし、微調整で精度を高めていくのが良い